Hallucinations in Large Language Models (LLM) like ChatGPT are here to stay, as recently confirmed by an OpenAI blogpost. But how do they affect users‘ trust and the way users interact with LLMs? In a recent paper (Ryser et al. 2025), we describe trust in LLMs as a dynamic, experience-based process rather than a fixed state. By looking at the factors influencing trust, we show how users adapt their trust based on factors like prior experience, perceived risk or decision stakes, and give recommendations on how to achieve the right level of trust.
Trust is a key success factor for adopting Large Language Models (LLM). A recent SAS study outlines the „trust dilemma“: The trust users put in LLM has to match their trustworthiness. Otherwise, there is a dual risk: organisations will either miss out on opportunities because they don’t trust the systems enough, or run risks like hallucinations if they trust too much.

But how do users make up their mind whether or not to trust such tools, and to what extent? In a qualitative study, we looked at experiences of hallucinations and how they affect the way users interact with LLMs. We developed a model of calibrated trust that shows how users navigate between undertrust (blanket rejection of any LLM output) and overtrust (blind acceptance). We show how this depends on a variety of factors: technical, contextual, human and axiological (values-based).
Hallucinations in LLM
Hallucinations in LLM are defined as output that sounds plausible but is incorrect. Root causes include flawed or biased training data, a misalignment between training objectives and user expectations, as well as limitations in decoding and inference strategies (Huang et al. 2025). Despite efforts to mitigate them, recent theoretical work shows that hallucinations cannot be fully eliminated, as no model can produce factually correct outputs for all possible inputs (Xu et al. 2025, Zhang & Zhang 2025).
To find out more about how experiences of LLM hallucinations influence users‘ trust in LLMs and their interactions with them, we conducted a qualitative study with 192 respondents (results shared here as open data). 82% of respondents claimed to be familiar with LLM hallucinations, while 68% reported personal experience. We found that hallucination experiences did not lead to a general loss of trust, but to changes in how users interact with LLMs (“It made me a bit suspicious, but I still don’t use ChatGPT any less“, said one respondent). However, it was a bit of a shock for some respondents to learn about hallucinations:
„now every answer AI has ever given me makes me feel insecure…“ – one respondent
Crucially, we found that trust was not lost, but recalibrated based on prior experience and the perceived relevance of the task:
“The greater the impact of an incorrect answer, the less I can check the correctness of the answer using my own knowledge and the more illogical the answers seem to me, the more likely I am to verify the answers” – another respondent
A Model for the Formation of Trust in LLM
Next, we combined aspects of the calibrated trust model by Lee & See (2004), Afroogh et al.’s (2024) trust-related factors and Blöbaum’s (2022) recursive trust calibration process into a model describing the dynamic formation of trust in the context of hallucination-prone LLM usage. The figure below shows how calibrated trust is achieved when a user’s trust matches the capability of an LLM. It also shows the various factors either increasing or decreasing trust, along with references to the literature (see our paper for details).
Our findings also suggest intuition as an additional factor that may support the early detection of implausible or hallucinated content through quick judgments about whether an LLM output seems plausible. Trust calibration is e.g. influenced by user expertise & domain knowledge or prior experience with LLMs. Some of the factors are debated or context-dependent: e.g. anthropomorphism may foster overtrust or undertrust, depending on user expectations.
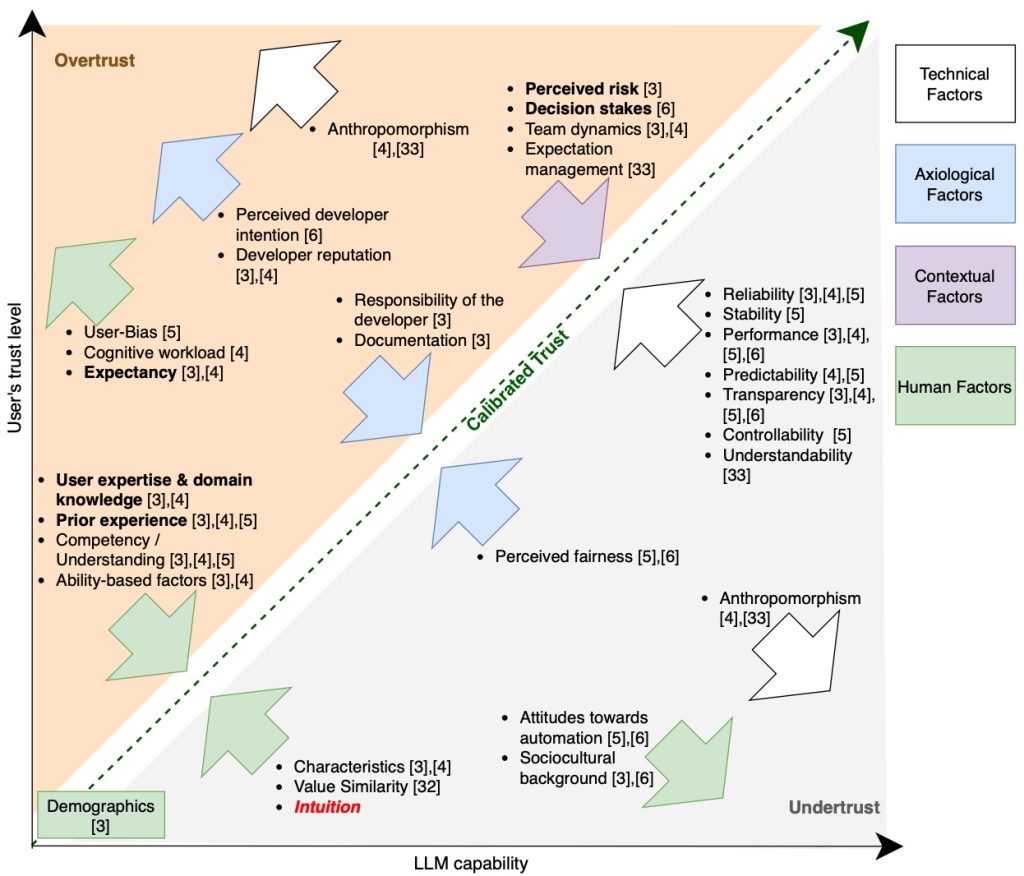
Extended calibrated trust model: Factors influencing trust calibration in LLM interactions (Ryser et al. 2025)
We also show how trust factors evolve through repeated user interaction with LLMs as users gradually develop calibrated trust through practical experience with given LLM outputs. Over time, these trust calibration loops lead to increased AI literacy.
Recommendations for users of LLMs:
Based on our findings, we give five recommendations on how to deal with hallucinations and develop an appropriate level of trust:
- Calibrate trust: Users should actively calibrate their trust in LLM outputs by considering the task’s relevance and their own level of domain knowledge.
- Verify contextually: By tailoring verification efforts to the perceived risk and relevance of the task, users can manage uncertainty efficiently.
- Integrate intuition into the trust assessment: Based on prior experience with LLMs, users should rely on their intuition for linguistic coherence, internal consistency, or implausibility to detect hallucinated LLM outputs—especially when output verification is not feasible.
- Build AI literacy: Developing a better understanding of how LLMs function and where their limitations lie is essential for responsible and context-sensitive use.
- Treat LLMs as assistants: A clear classification of LLMs as a supporting tool promotes an appropriate approach to the limits of LLMs.
Thus, users should treat LLMs carefully and reflect on their own trust and how it develops over time. Similarly, further research is indicated, especially over longer periods of time, to see how trust develops. Researchers in the area of LLM should be mindful of hallucinations and how they may limit the tools‘ usefulness. They should also reflect on the variety of factors influencing trust, including human factors as outlined here.
References:
Afroogh, S., A. Akbari, E. Malone, M. Kargar, & H. Alambeigi, “Trust in AI: progress, challenges, and future directions,” Humanit. Soc. Sci. Commun., vol. 11, no. 1, p. 1568, Nov. 2024, doi:10.1057/s41599-024-04044-8.
Blöbaum, B., Vertrauen, Misstrauen und Medien. Wiesbaden: Springer Fachmedien Wiesbaden, 2022. doi: 10.1007/978-3-658-38558-3.
Huang, L. et al., “A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions,” ACM Trans. Inf. Syst., vol. 43, no. 2, pp. 1–55, Mar. 2025, doi:10.1145/3703155.
Lee, J. D. & K. A. See, “Trust in Automation: Designing for Appropriate Reliance,” Hum. Factors, vol. 46, no. 1, pp. 50–80, Mar. 2004, doi:10.1518/hfes.46.1.50_30392.
Xu, Z., S. Jain, & M. Kankanhalli, “Hallucination is Inevitable: An Innate Limitation of Large Language Models,” Feb. 13, 2025, arXiv: arXiv:2401.11817. doi: 10.48550/arXiv.2401.11817.
Zhang, W. & J. Zhang, “Hallucination Mitigation for Retrieval-Augmented Large Language Models: A Review,” Mathematics, vol. 13, no. 5, p. 856, Mar. 2025, doi: 10.3390/math13050856.
Blogpost based on:
Ryser, A., Allwein, F., & Schlippe, T. (2025). Calibrated Trust in Dealing with LLM Hallucinations: A Qualitative Study. 3rd International Conference on Foundation and Large Language Models. FLLM2025, Vienna. Preprint available here.